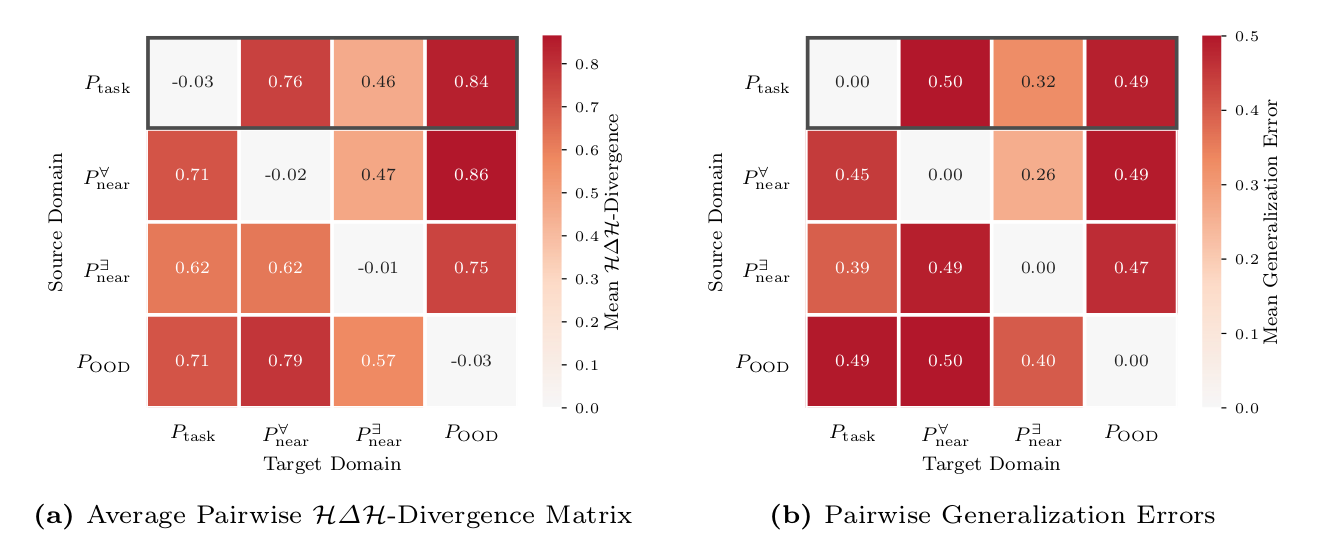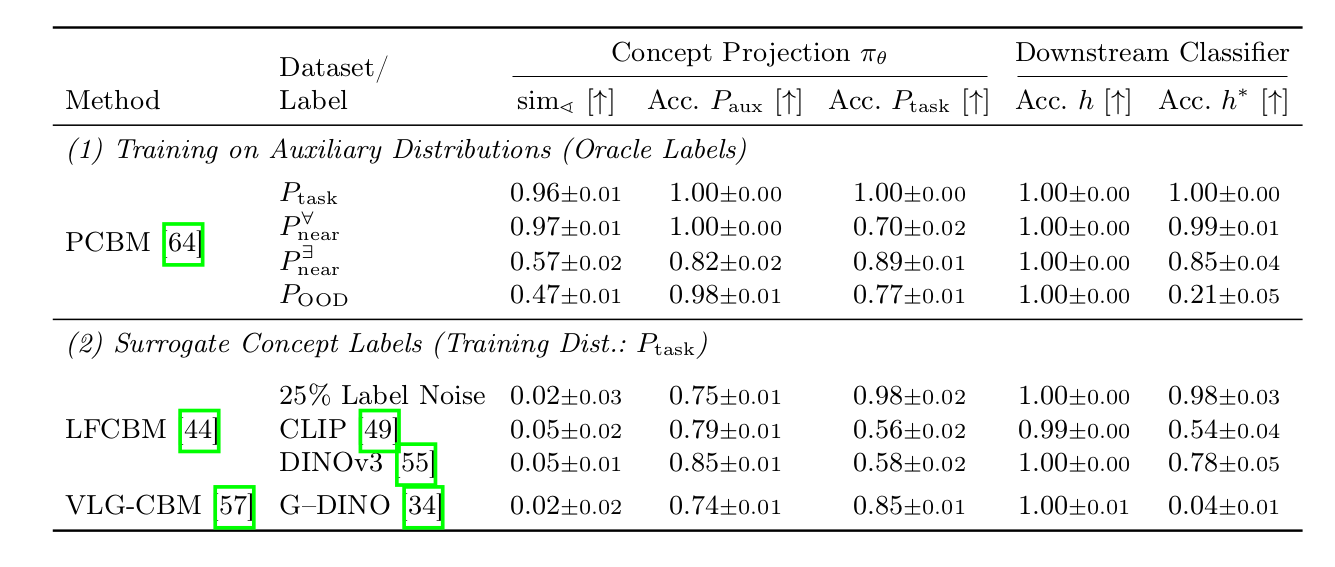Abstract
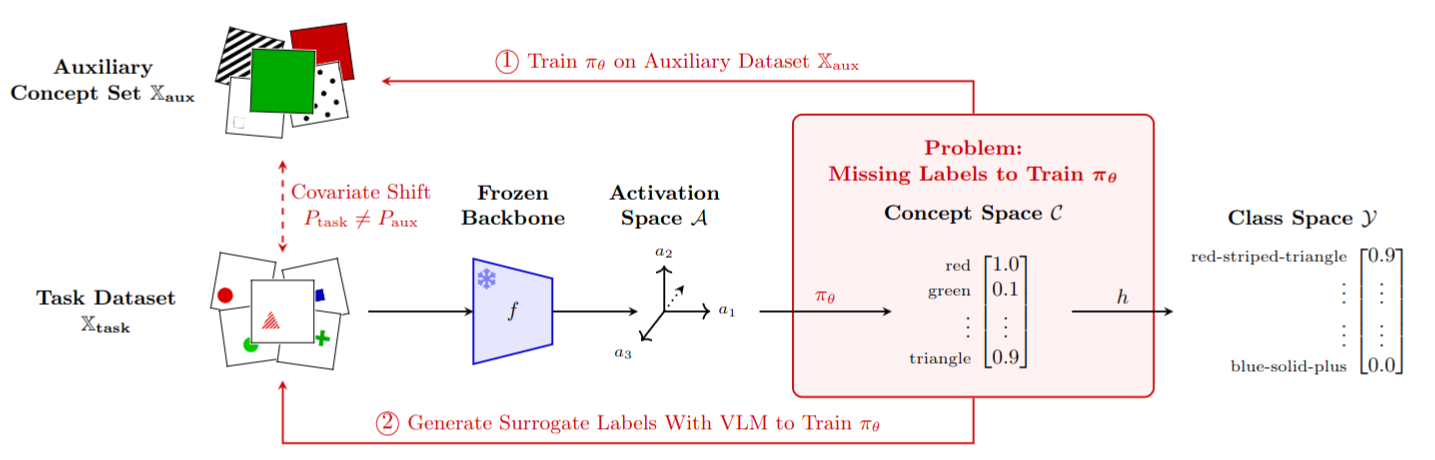
Human decision-making interprets the world through high-level concepts, such as recognizing a bird by its belly color. To bridge the gap between opaque deep learning representations and human understanding, Post-Hoc Concept Bottleneck Models (post-hoc CBMs) project latent features onto interpretable concept spaces using auxiliary datasets or vision-language models.
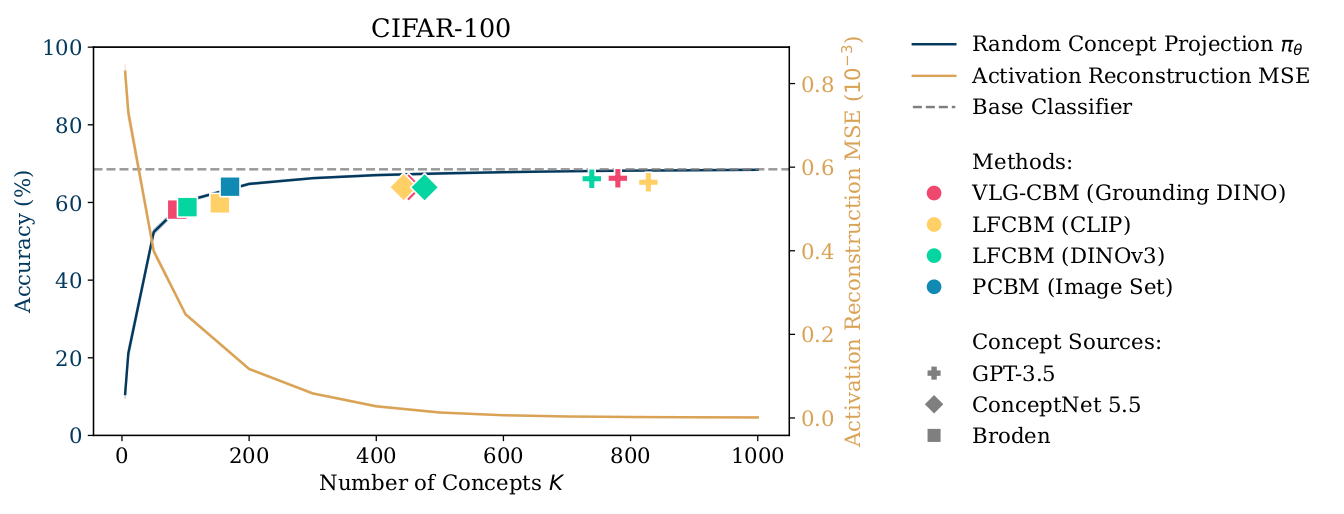
However, relying on target task accuracy as the primary measure of post-hoc CBM success obscures whether the learned concepts are semantically meaningful or merely predictive artifacts. For example, random concept projections can achieve competitive accuracy despite being semantically meaningless.
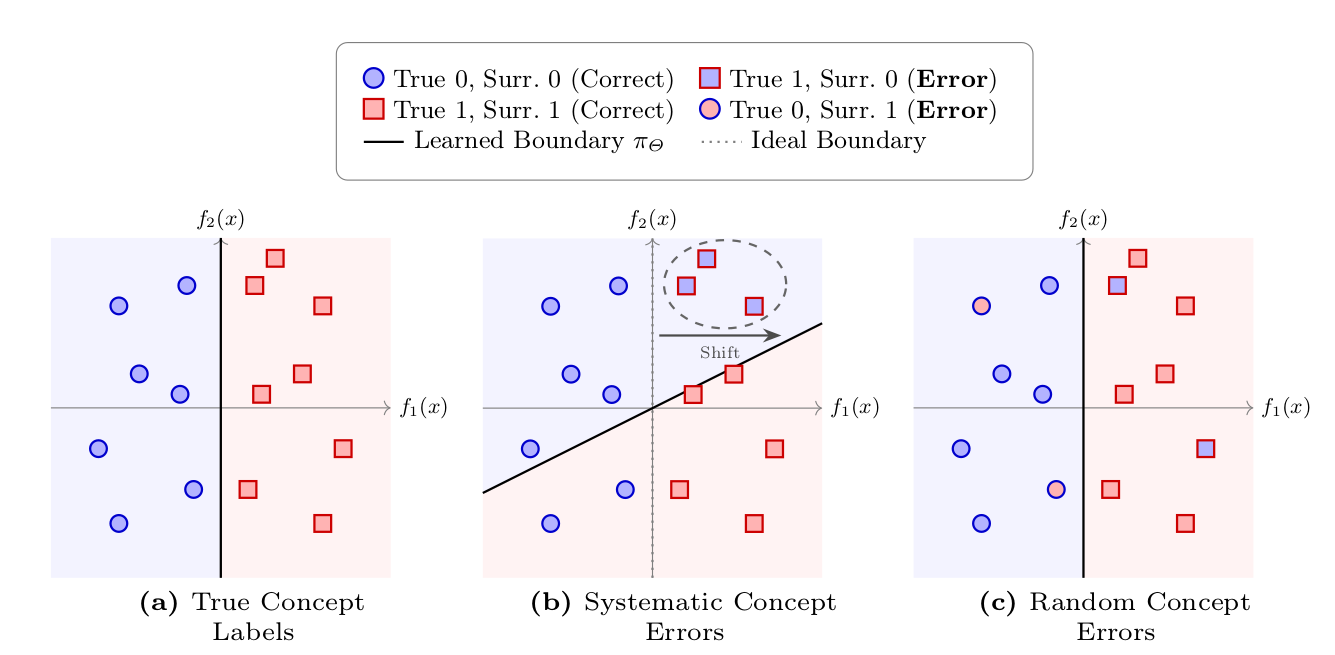
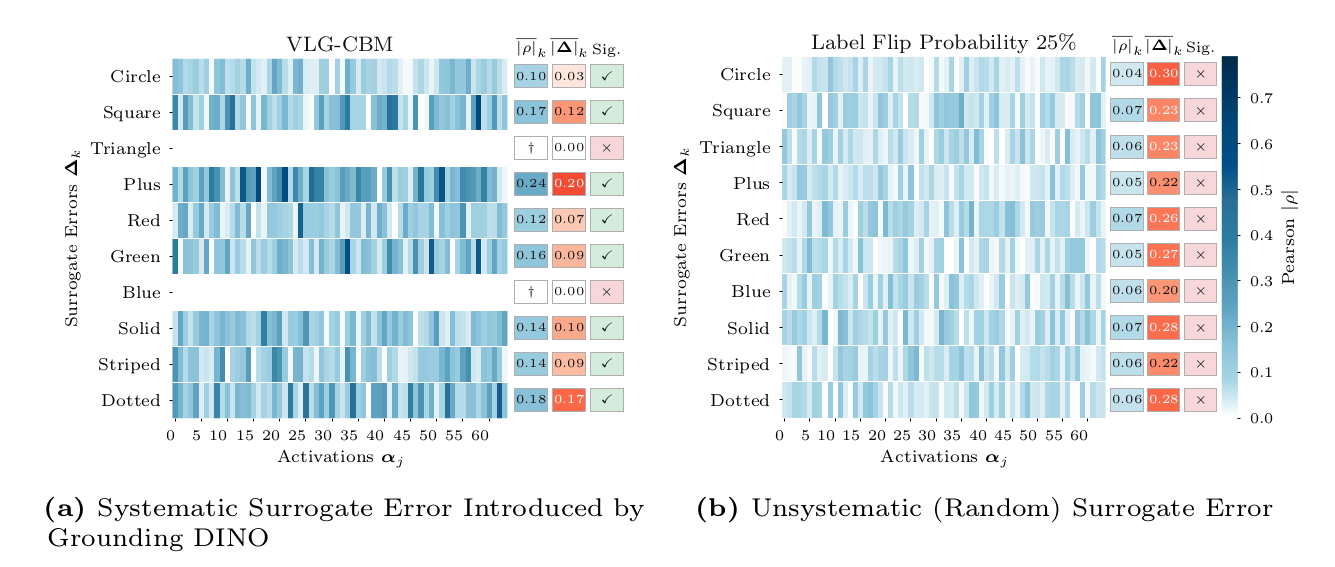
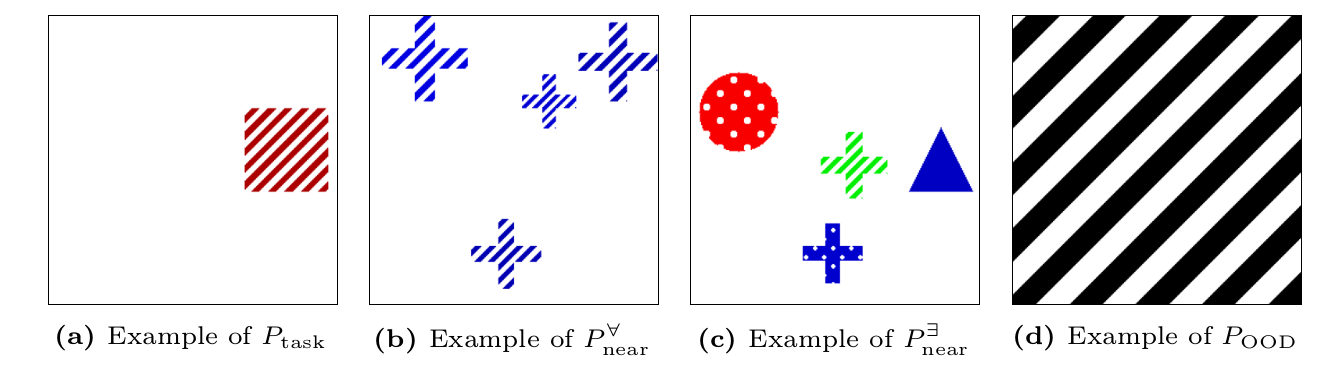
In this work, we analyze the learned projections directly and identify two failure cases: First, for concept projections learned from auxiliary data, covariate shifts can lead to unfaithful concept representations for the target task. In particular, we provide an upper bound on the error introduced by this shift. Second, systematic label noise in surrogate concept labels generated by vision-language models leads to unfaithful projections. After formalizing these failure modes, we introduce novel metrics that decouple concept faithfulness from predictive accuracy. Our empirical results across real-world and synthetic benchmarks confirm that these metrics identify unfaithful behaviors that standard accuracy-based evaluation fails to detect.